Ce qui est traité dans cet article :
- Distinction des rôles : Explication des différences fondamentales entre le Data Scientist et le Data Engineer en termes de responsabilités et de missions.
- Outils et langages : Présentation des outils, langages et logiciels spécifiques utilisés par les Data Scientists et les Data Engineers.
- Formation et parcours : Aperçu des formations typiques et des parcours académiques des professionnels de la Data Science et du Data Engineering.
- Salaires et recrutement : Analyse des tendances salariales et des perspectives de recrutement pour ces deux métiers.
Les questions clés de l’article :
- Quelle est la principale différence entre un Data Scientist et un Data Engineer ? Le Data Scientist se concentre sur l’exploitation des données pour en tirer des enseignements et prendre des décisions, tandis que le Data Engineer développe et met en place des architectures data pour préparer le terrain aux Data Scientists.
- Quels sont les outils couramment utilisés par les Data Engineers ? Les Data Engineers travaillent souvent avec des outils comme SAP, Oracle, Cassandra, MySQL, Redis, Riak, neo4j, Hive, Sqoop et PostgreSQL.
- Quels langages sont privilégiés par les Data Scientists ? Les Data Scientists utilisent principalement Python et R, avec des bibliothèques comme ggplot2, Pandas, Scikit-Learn, NumPy, Matplotlib et Statsmodels.
- Quelle est la formation typique d’un Data Scientist ? Les Data Scientists ont souvent une formation en mathématiques, statistiques, économétrie, physique ou biologie, avec un sens aiguisé du business.
- Quelle est la formation typique d’un Data Engineer ? Les Data Engineers ont généralement une formation axée sur l’informatique, l’ingénierie ou les systèmes d’information.
- Quels sont les salaires moyens des Data Scientists et Data Engineers ? Les salaires sont assez équivalents, avec un Data Scientist gagnant entre 41k et 55k euros par an et un Data Engineer entre 40k et 53k euros par an.
En Data Science, deux métiers doivent être distingués : Data Scientist et Data Engineer. Si vous n’êtes pas encore sûr de bien saisir les différences entre les deux fonctions, si vous voulez avoir l’esprit au clair sur ce sujet, cet article est pour vous.
Nous allons voir quelles sont les principales différences entre les deux, à tous les niveaux : rôle, compétences, outils & langages utilisés, formation, salaires, etc.
| Critères | Data Engineer | Data Scientist |
|---|---|---|
| Rôle principal | Construit et maintient les infrastructures de données. | Analyse et interprète les données pour en tirer des insights. |
| Outils & Langages | SQL, Hadoop, Spark, Kafka, Azure, outils ETL. | Python, R, TensorFlow, PyTorch, outils de visualisation, SQL. |
| Formation typique | Informatique, ingénierie, systèmes d'information. | Mathématiques, statistiques, économétrie, physique, biologie, business. |
| Tâches courantes | Création d'entrepôts de données, optimisation des performances, sécurisation des données. | Création de modèles prédictifs, analyse statistique, visualisation des données, présentation des résultats aux décideurs. |
| Tendances du marché | Demande croissante en raison de la nécessité de structures de données solides et fiables. | Évolution du rôle avec l'automatisation croissante et l'intégration de l'IA, nécessité d'une collaboration étroite avec les Data Engineers. |
Sommaire
Data Scientist vs Data Engineer – Rôle & Responsabilités
Les deux métiers se complètent :
- Le Data Engineer développe, teste, met en place des architectures data. Il créé des bases de données et organise la tuyauterie, c’est-à-dire les flux de données entre les sources et les bases de stockage. Le Data Engineer prépare le terrain au Data Scientist et aux autres professionels de la data (les Data Analysts, notamment).
- Le Data Scientist a pour rôle d’exploiter les données, d’en faire quelque chose, d’en tirer des enseignements, de prendre des décisions à partir d’elles. Son métier consiste à faire parler la donnée. Il transforme des données brutes en informations utiles, en insights. Il utilise pour cela des techniques de Machine Learning. Il détecte des patterns, construit des modèles de données.

Le Data Engineer est confronté à des données brutes, dont certaines sont invalides, suspectes, erronées, mal-formatées. Il traque ces dysfonctionnements, recommande et parfois se charge de l’implémentation de solutions pour améliorer la fiabilité, l’efficience et la qualité des données. Il est amené à utiliser une grande variété de langages et d’outils pour réussir à connecter des systèmes hétérogènes entre eux et identifier des moyens de collecter de nouvelles données en provenance d’autres sources. Le Data Engineer doit s’assurer que l’architecture data en place répond aux attentes et aux besoins des Data Scientists et des autres parties prenantes.
Les données auxquelles le Data Scientist a affaire ont déjà été manipulées, ont déjà fait l’objet d’un nettoyage pour qu’il puisse se concentrer sur l’essentiel : mettre en place des programmes d’analyse avancés, des programmes de machine learning, des méthodes statistiques dans le but de construire des modèles prédictifs. Pour construire ces modèles, le Data Scientist a besoin de bien connaître l’entreprise dans laquelle il travaille et son secteur d’activité. Les informations que doit rechercher un Data Scientist, les insights qu’il doit essayer de mettre au jour, sont par définition spécifiques à une entreprise ou, plus largement, à un métier.
Ses compétences excèdent de très loin la simple sphère technique. Il est parfois amené à explorer de grands volumes de données pour identifier des patterns cachés. Une fois que le Data Scientist a fini son travail d’analyse, il doit en présenter les résultats aux personnes clés de l’entreprise, aux décideurs. De manière à la fois claire et précise, ce qui suppose des compétences humaines et orales développées, mais aussi des compétences en Data Visualization. Le Data Scientist se doit d’être un bon communicant.
Les Data Engineers et les Data Scientists sont, comme on le voit, inséparables, complémentaires. Ils travaillent ensemble pour faire parler la donnée et en tirer des enseignements permettant aux décideurs de prendre de meilleures décisions.
Pour aller plus, découvrez notre guide complet sur les compétences d’un bon Data Scientist.
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisData Scientist vs Data Engineer – Langages, outils et logiciels
Les différences en matière de compétences se traduisent logiquement par des différences en matière de langages, d’outils et de logiciels utilisés.
Vous verrez souvent les Data Engineers travailler avec des outils comme SAP, Oracle, Cassandra, MySQL, Redis, Riak, neo4j, Hive, Sqoop ou encore PostgreSQL.
De leur côté, les Data Scientists auront tendance à utiliser des langages comme SPSS, Python, R, SAS pour construire leurs modèles. D’ailleurs, dans cette liste, les deux principaux langages sont clairement Python et R. Quand on travaille avec Python ou R pour faire de la Data Science, on est amené à utiliser des bibliothèques du type ggplot2 pour faire de la Data Visualization dans R ou les bibliothèques Pandas si on est sur Python. Les modules Scikit-Learn, NumPy, Matplotlib ou encore Statsmodels sont eux aussi très utilisés.
Ça c’est pour l’open source, mais on trouvera aussi des outils commerciaux comme SAS, SPSS, Tableau, Rapidminer, Matlab Gephi et Excel. Ces outils font souvent partie de la boîte à outils du Data Scientist. Comme vous pouvez le constater, il y a beaucoup d’outils de Data Vizualisation.
Les outils, langages et logiciels utilisés à la fois par les Data Engineers et les Data Scientists sont, vous l’aurez peut-être déjà deviné, Scala, Java, C#…
Scala est plus populaire auprès des Data Engineers grâce à l’intégration avec Spark, qui permet d’implémenter des flux ETL.
Le langage Java est quant à lui de plus en plus populaire auprès des Data Scientists mais reste un langage peu utilisé.
Data Scientist vs Data Engineer – Formation
Les Data Scientists et les Data Engineers ont des parcours académiques et professionnels variés, mais ils partagent tous les deux une solide base en informatique :
- Les Data Scientists ont souvent une formation en mathématiques, statistiques, économétrie ou même en physique et biologie. Ces domaines fournissent les compétences analytiques nécessaires pour interpréter et modéliser des données complexes. En plus de ces compétences techniques, un sens aiguisé du business est souvent essentiel pour les Data Scientists afin de traduire les analyses en recommandations stratégiques. Ils sont responsables de l’extraction d’insights à partir de données et de la création de modèles mathématiques pour permettre des prédictions.
- Les Data Engineers, quant à eux, ont généralement une formation plus axée sur l’informatique, l’ingénierie ou les systèmes d’information. Ils sont spécialisés dans la conception, la construction et la maintenance des infrastructures qui collectent, stockent et analysent les données. Leur rôle est de s’assurer que les données nécessaires aux Data Scientists sont disponibles dans le bon format et sont précises. Les données, lorsqu’elles sont collectées, peuvent être complexes et désordonnées. Les Data Engineers jouent un rôle crucial dans la préparation de ces données pour qu’elles soient analysées efficacement.
Data Scientist vs Data Engineer – Salaires & Recrutement
Le salaire d’un Data Scientist s’établit entre 41k et 55k par an, selon Glassdoor.
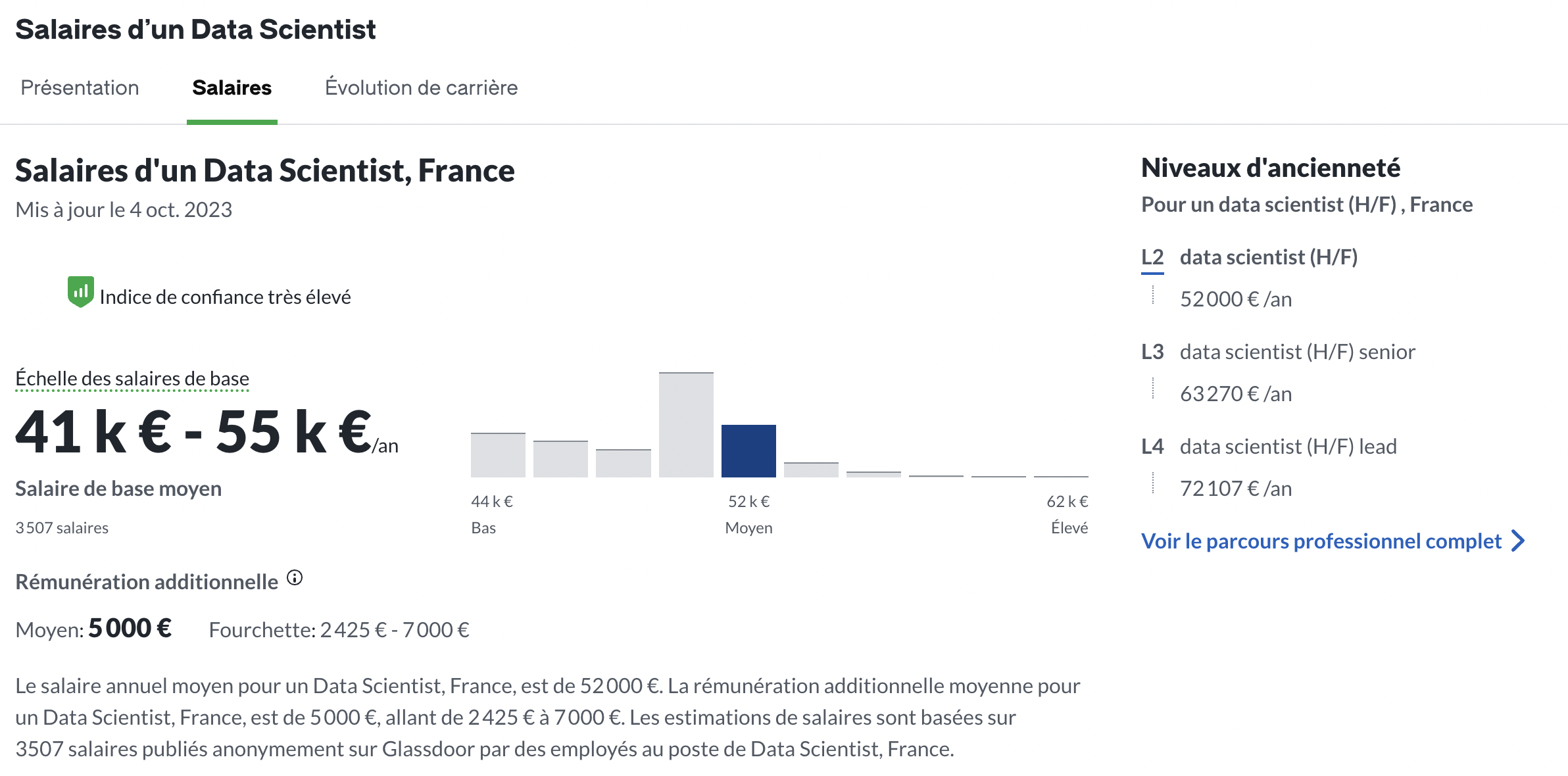
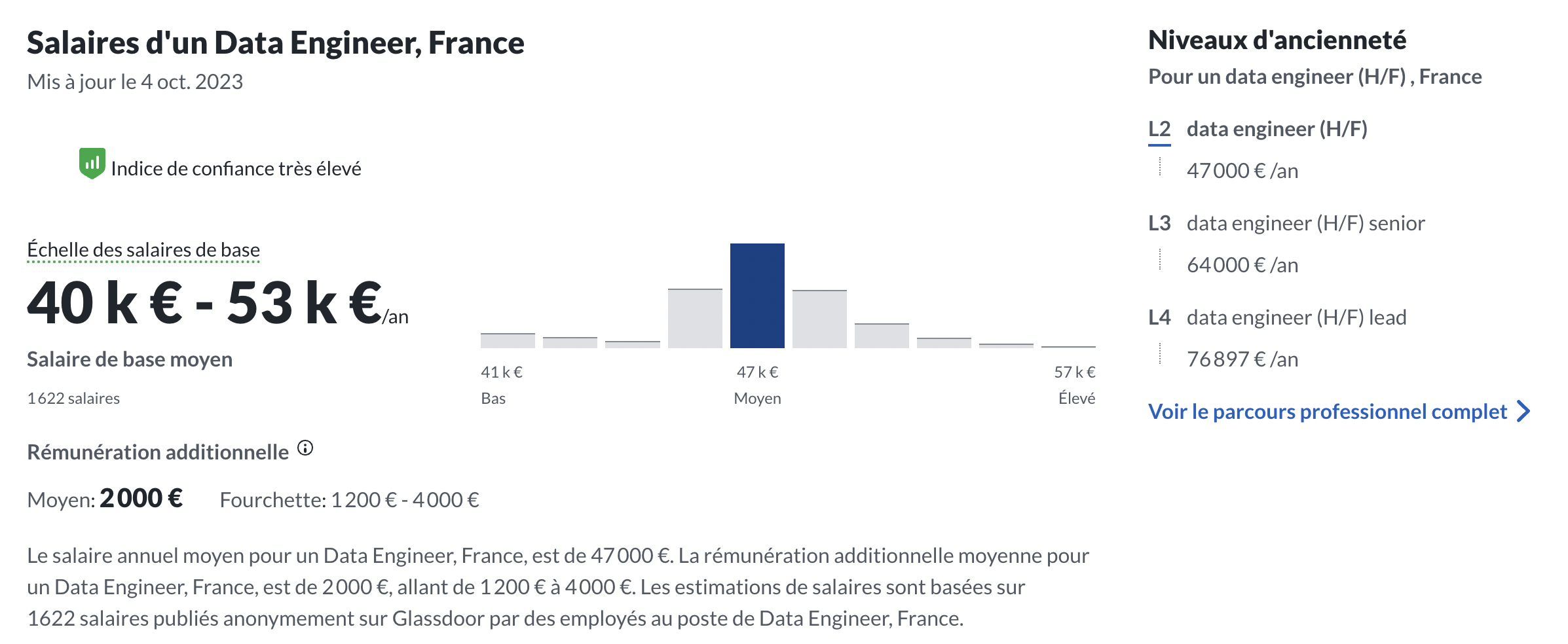
Toujours selon Glassdoor, le salaire d’un Data Engineer s’établit entre 40 et 53 k euros par an. On est donc sur des salaires assez équivalents, avec un rattrapage ces derniers années du salaire des Data Engineers. Aujourd’hui, un Data Engineer est payé autant voire mieux qu’un Data Scientist. Les salaires affichés sur Glassdoor sont similaires à ceux affichés sur le site Data Recrutement, donc il y a tout lieu de penser qu’ils sont fiables.
Tendances & perspectives
La distinction entre le Data Scientist et le Data Engineer a longtemps alimenté les discussions. Toutefois, les tendances actuelles indiquent un changement significatif. Bien que la data science ait connu une montée en flèche en termes de demande, c’est désormais le rôle du Data Engineer qui semble être sous les projecteurs, éclipsant quelque peu les Data Scientists.
Plusieurs raisons peuvent expliquer cette évolution. Malgré l’essor des outils d’automatisation, le rôle crucial du Data Engineer dans la préparation et la structuration des données demeure incontestable. Les entreprises valorisent de plus en plus les experts capables de mettre en place des infrastructures robustes pour la gestion des données.
Quant à la diminution de l’engouement pour les Data Scientists, elle pourrait être attribuée aux avancées en intelligence artificielle et en machine learning. Les solutions basées sur l’IA prennent en charge de nombreuses fonctions autrefois dévolues aux Data Scientists. Cela souligne l’importance d’une collaboration renforcée avec les Data Engineers pour assurer l’intégrité et la pertinence des données. Dans ce contexte en mutation, une chose est claire : la complémentarité entre ces deux métiers est plus essentielle que jamais pour naviguer dans le paysage data actuel.
Laisser un commentaire