La plupart des entreprises sont assises sur une mine d’or. L’or, ce sont les données clients. La mine, c’est le Data Warehouse. Mais les données sont en général sous-exploitées car les entreprises ne parviennent pas à les faire sortir du Data Warehouse pour les mettre pleinement à disposition des applicatifs métiers : CRM, Marketing Automation, Service Client, outils commerciaux…
Les Reverse ETL désignent une nouvelle famille de solutions permettant de faire descendre les données du Data Warehouse dans les différents outils métiers, au service des équipes métiers. Les Reverse ETL ont vocation à devenir la brique clé de la stack data moderne, celle qui permettra de valoriser pleinement les données de votre entrepôt de données.
Nous allons voir en quoi consiste un Reverse ETL, ce qui distingue un Reverse ETL d’un ETL, d’une CDP, d’une solution iPaaS. Nous vous présenterons à la fin les principaux acteurs de ce marché naissant : deux acteurs US (Census et Hightouch) et un acteur français prometteur : Octolis.
Sommaire :
Qu’est-ce que le Reverse ETL ? [Définition]
Définition simple du Reverse ETL
Il est difficile de donner une définition du Reverse ETL sans parler pour commencer de l’ETL. Pourtant, nous n’allons pas prendre ce détour car nous aurons l’occasion tout à l’heure de parler plus en détail de la différence entre un Reverse ETL et un ETL, tant du point de vue fonctionnel (finalités) que technique (mode d’intégration des données).
Un Reverse ETL, en synthèse, est une solution d’intégration des données souple qui permet de mettre les données du Data Warehouse à disposition des systèmes opérationnels de l’entreprise : CRM, Marketing Automation, Service Client, Outils commerciaux, outils publicitaires…
Les Reverse ETL désignent une nouvelle famille de solutions technologiques qui a vocation à devenir l’une des pièces fondamentales de la stack data moderne. Comme toute « solution », le Reverse ETL est une réponse à une difficulté, un problème rencontré par pratiquement toutes les entreprises data-driven ou qui souhaitent le devenir.
Ce problème, on peut le formuler simplement : l’entreprise dispose d’un Data Warehouse construit dans le Cloud à partir d’une plateforme de type Amazon Redshift, Snowflake, BigQuery…Cet entrepôt de données cloud joue le rôle de base de données maîtresse de l’entreprise, de Référentiel Client Unique. Mais – et c’est là que réside le problème – les données du Data Warehouse sont sous-exploitées par les équipes métiers car il n’existe pas le pipeline de données qui permettrait de facilement distribuer les données stockées dans cette base aux différents applicatifs métier. Dit autrement : l’entreprise dispose d’un nombre considérable de données bien organisées dans le Data Warehouse, mais ces données sont mal ou trop peu utilisées par le Marketing, le Service Client, les Sales. Dans les faits, toutes ces données clients aux potentialités d’activation multiples sont surtout utilisées pour faire de la BI, créer des rapports et des tableaux de bord. C’est déjà bien, mais il est possible d’aller beaucoup plus loin. Il faut aller plus loin pour devenir véritablement data-driven. Comment ? En utilisant justement un Reverse ETL.
Une solution Reverse ETL permet de faire facilement et souplement descendre les données stockées dans le Data Warehouse dans les applicatifs de type CRM, Marketing Automation, etc. Il distribue la donnée stockée dans votre base maître (vos différentes bases unifiées) au métier, sans complexité.
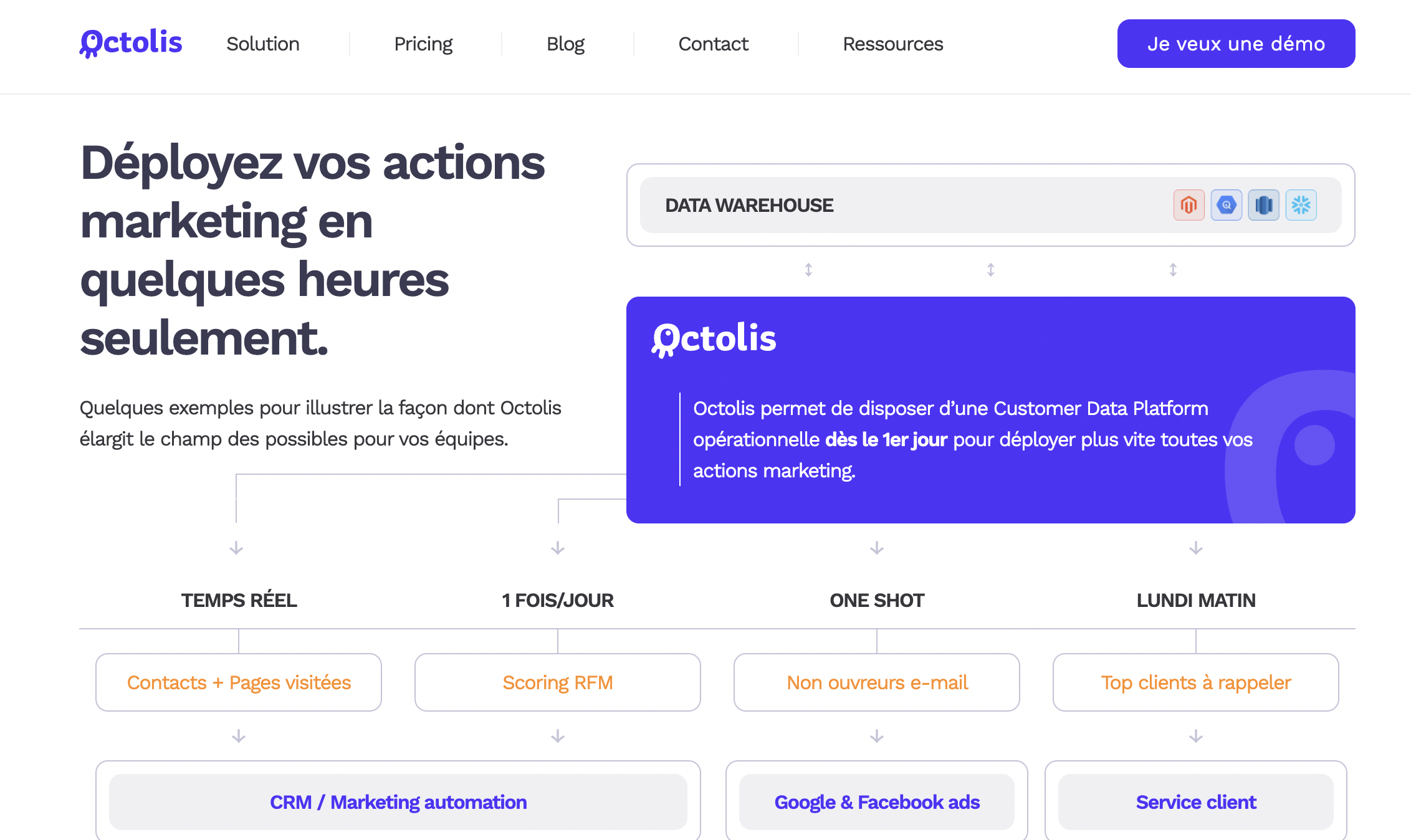
Le Reverse ETL facile l’accès et l’utilisation des données de l’entrepôt de données par les équipes métier.
Zoom sur quelques cas d’usage du Reverse ETL
Dans notre activité de conseil en Données Clients, nous faisons régulièrement le constat de la frustration des équipes métier qui ne parviennent pas à obtenir les données dont elles auraient besoin – données qui sont pourtant bien là, dans le Data Warehouse. L’IT ne parvient pas à répondre dans les temps aux demandes de plus en plus nombreuses des équipes métier.
Par exemple :
- L’équipe marketing – CRM aimerait utiliser la fréquence d’achat des clients dans sa solution de Marketing Automation pour créer des scénarios plus puissants…hélas, elle n’y parvient pas. Pas plus qu’elle n’arrive à intégrer le score RFM et les recommandations produits dans la solution de Marketing Automation pour créer un scénario d’up-sell.
- Les commerciaux aimeraient voir affichée dans Salesforce la consommation de crédits des contacts et des comptes. Ils seraient également très heureux de pouvoir intégrer dans le CRM Commercial les scores de leads et les scores de chaleur pour mieux prioriser les leads à traiter dans Salesforce ou HubSpot. Mais c’est peine perdue…
- Le département comptable voudrait que les attributs clients soient synchronisés dans son logiciel de comptabilité ou leur ERP…mais a fini par y renoncer face à la perspective déprimante de devoir passer par une API.
- Le Service Client voudrait que les données relatives à l’utilisation des services soient accessibles dans Zendesk…Cela demeure un vœu pieu.
Eh bien le Reverse ETL est l’outil qui va permettre de résoudre toutes ces frustrations et de réaliser ce que les équipes métier ont toujours rêvé : obtenir facilement les données, les segments, les agrégats dont elles ont besoin pour exploiter pleinement les applicatifs métier. Car le problème est bien là : l’entreprise investit dans des solutions coûteuses mais les sous-utilisent par manque de données clients accessibles. Vous avez beau avoir une Ferrari, un logiciel ultra puissant, si vous n’avez pas le carburant (les données clients), votre Ferrari n’avancera pas. Ce constat est particulièrement criant dans le cas des outils de Marketing Automation. Les scénarios complexes et avancés (upsell, relance de panier abandonné, réactivation…) reposent tous sur des agrégats complexes de données, qu’il est (était) souvent fastidieux d’obtenir.
C’est le manque d’intégration des données qui limite (parfois drastiquement) l’utilisation des outils de la stack marketing. Ironiquement, le Data Warehouse qui a été conçu pour désiloter les données de l’organisation a tendance à devenir lui-même un silo en l’absence de technologies de type Reverse ETL. Le Reverse ETL est la pièce de la stack data qui permet de rendre les outils de la stack marketing plus puissants et les actions plus performantes. Le Reverse ETL est la solution qui fait le pont entre votre Data Warehouse et tous les outils métiers.
L’émergence de cette nouvelle technologie que constitue le Reverse ETL s’inscrit dans une nouvelle approche marketing appelée « Operational Analytics« . Cette approche consiste à mettre la donnée au service des équipes opérationnelles, pour des cas d’usage opérationnels (marketing, commerciaux, de support…). Elle se distingue de l’approche classique qui consiste à n’utiliser les données structurées du Data Warehouse qu’à des finalités de reporting et de BI. Avec l’Operational Analytics, la donnée du Data Warehouse n’est plus seulement au service de l’équipe BI : elle irrige tous les départements de l’entreprise et nourrit tous les systèmes opérationnels. L’Operational Analytics rend les données clients de l’entrepôt de données actionnables. L’Operational Analytics est la toile de fond sur laquelle les Reverse ETL ont émergé. Le Reverse ETL est l’outil qui répond à cette nouvelle pratique.
Pour aller plus loin, nous vous invitons à découvrir notre guide « Operational Analytics – Une nouvelle approche pour réellement actionner vos données« .
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisQuelle différence entre un Reverse ETL et les autres briques de la stack data moderne ? (ETL, CDP, iPaaS)
Une approche efficace pour définir quelque chose est de la distinguer de ce qu’elle n’est pas. C’est une manière de marquer sa différence, sa spécificité, son essence. Nous allons voir en quoi le Reverse ETL se distingue de l’ETL, de la Customer Data Platform (CDP) et des solutions iPaaS.
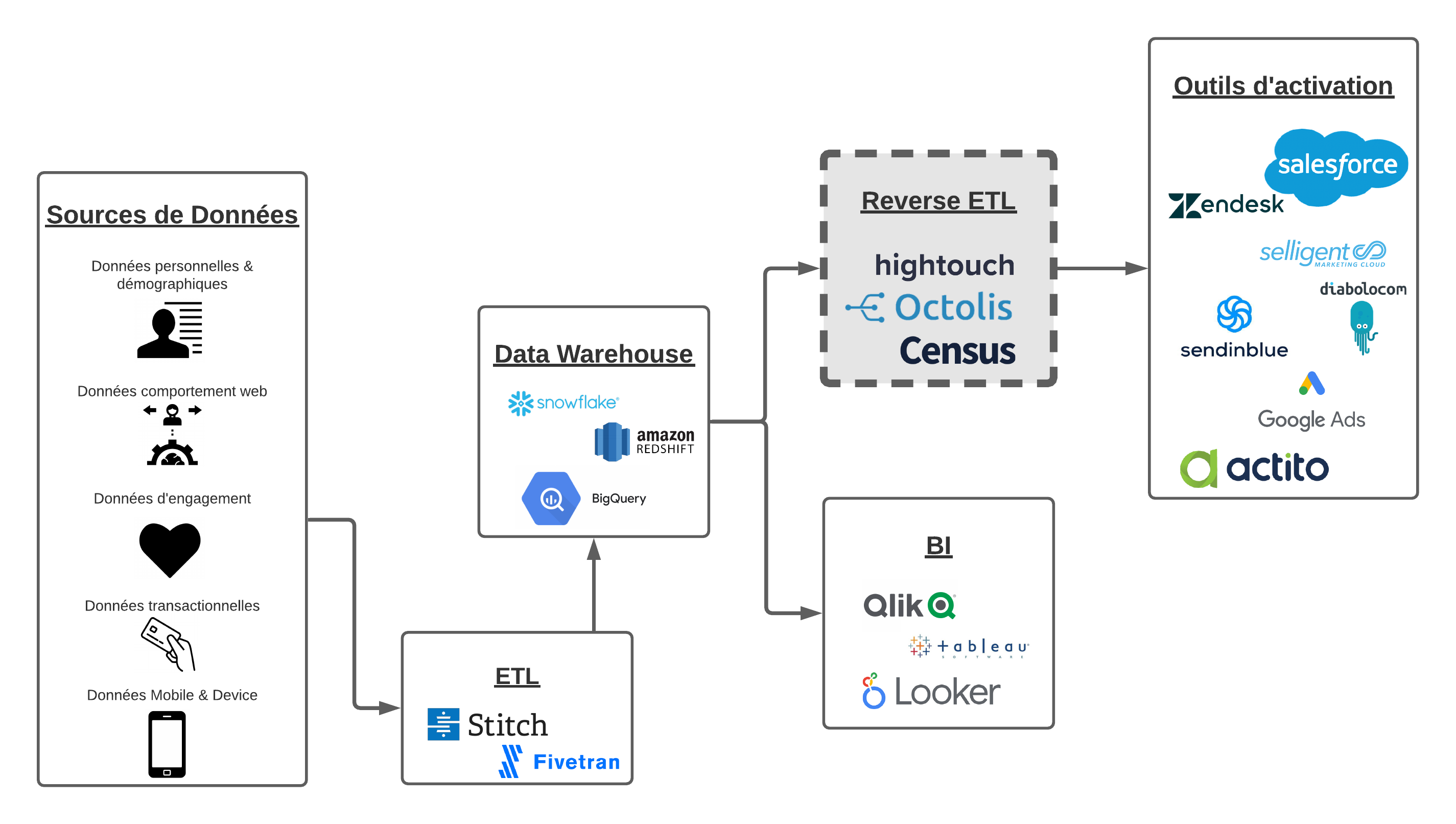
Différence entre un ETL et un Reverse ETL
Un outil ETL est une solution qui réalise le process d’Extract – Transform – Load. Les outils ETL traditionnels ont pour fonction d’extraire les données issues des différences sources de data de l’entreprise, de les transformer et ensuite de les charger dans la base de données maître, c’est-à-dire dans le Data Warehouse. Un outil ETL est à l’interface des sources de données et du Data Warehouse. Il intègre les données multiples de l’entreprise dans l’entrepôt en y appliquant au préalable les transformations nécessaires pour que ces données respectent le format et le modèle de données designés dans le Data Warehouse. Le schéma ci-dessus montre bien la place de l’outil ETL dans une stack data.
Tandis que l’ETL fait en quelque chose monter les données sources dans le Data Warehouse, le Reverse ETL fait redescendre ces données dans les applicatifs. Le Reverse ETL synchronise les données du Data Warehouse dans les outils métiers et autres outils d’activation. Pour prendre une autre image :
- L’ETL déplace les données DANS le Data Warehouse. Il charge les données issues des data sources, il les fait entrer dans l’entrepôt de données.
- Le Reverse ETL fait sortir les données du Data Warehouse pour les distribuer aux applicatifs métiers après préparation/transformation.
D’où d’ailleurs le nom : Reverse ETL. La fonction du Reverse ETL est inverse de celle des outils ETL ou de leur successeur : les ELT. En effet, un outil ELT a beau transformer les données après les avoir chargées dans la base de données (« Transform » vient après « Load »), la finalité d’un outil ELT reste de charger les données dans le Data Warehouse et de les transformer en vue de les redistribuer aux outils de BI dans lesquels les équipes Data s’amuseront à créer de beaux reportings. Avec l’ELT, on reste dans le monde de l’ETL. L’ETL est au service de l’unification des données. Avec le Reverse ETL, on entre dans un autre univers. La finalité est radicalement différente : elle est de délivrer la donnée au service des équipes métier.
Ce qui ne signifie pas que ETL et Reverse ETL s’opposent. Les deux sont complémentaires et en un sens le Reverse ETL complète la boucle de l’intégration data. Jusqu’à présent, on avait des outils (les ETL) qui permettaient d’unifier dans une base de type DWH les données issues de tous les systèmes de l’entreprise, mais il manquait des outils pour correctement redistribuer ces données une fois transformées, unifiées, agrégées, scorées, segmentées aux outils et applicatifs. Le seul moyen de connecter les Données du DWH aux applicatifs était de passer par des APIs, ce qui entraînait des coûts/challenges importants de paramétrage et maintenance. Avec les Reverse ETL, la boucle est bouclée.
Différence entre une Customer Data Platform et un Reverse ETL
Les Customer Data Platforms font parler d’elles depuis quelques années. Le marché de la CDP explose. Pour beaucoup, la CDP est une réponse à tous les problèmes data, le Graal du Data Management. Nous sommes les premiers à reconnaître la puissance de ces solutions sur l’étagère qui permettent d’unifier les données clients, de construire un Référentiel Client Unique, de créer des segments, des scores et des agrégats redistribuables aux outils métiers. Nous avons même réalisé un Livre blanc sur le sujet de la CDP.
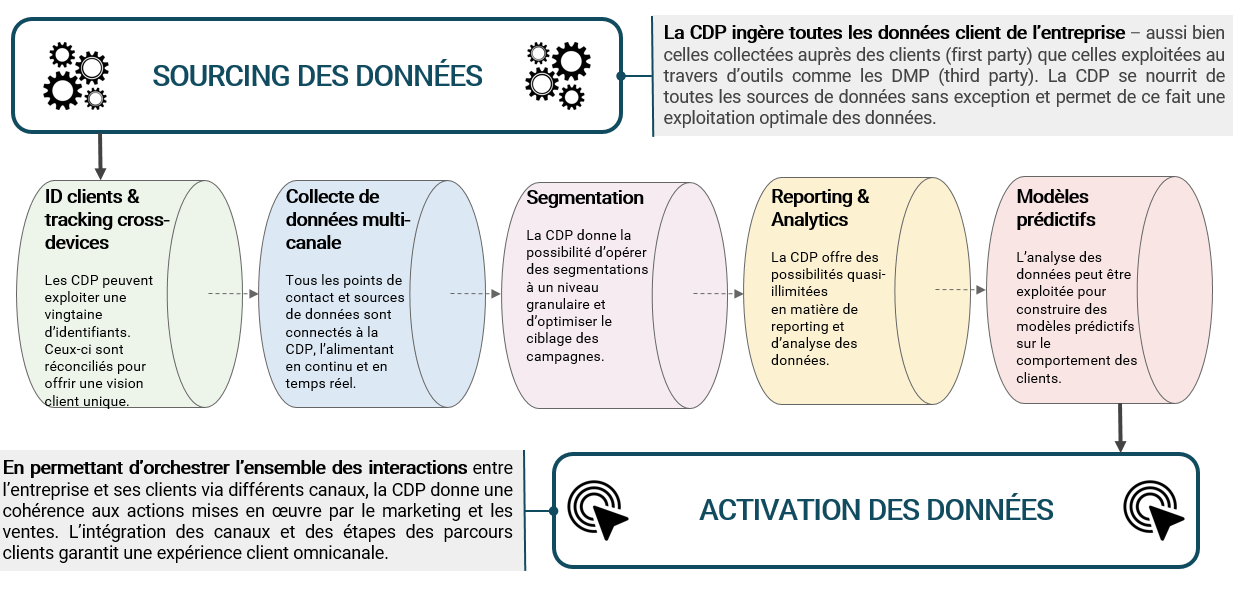
Soyons honnête, les CDP remplissent à peu près la même fonction que les Reverse ETL : elles permettent de synchroniser les données de la base de données dans les applicatifs métiers. Mais la CDP a une limite importante qui est sa rigidité. Une Customer Data Platform impose un ou des modèles de données, et en tous cas ne permet pas de créer tous les modèles de données sur-mesure dont votre entreprise peut avoir besoin pour ses cas d’usage métier. Elle n’a pas la souplesse des Data Warehouses Cloud et des outils Reverse ETL qui viennent s’y greffer. Les CDP propriétaires ont deux autres inconvénients :
- Leur prix, souvent très élevé. En tous cas bien plus élevé que les solutions consistant à associer un Data Warehoure Cloud à un outil de type Reverse ETL…
- Elle a un effet pervers qui est de favoriser une absence d’alignement et de coopération des équipes data & marketing. L’une des propositions de valeur des CDP est d’autonomiser les équipes marketing vis-à-vis de la DSI. C’est très bien, évidemment ! Mais pour les cas d’usage complexes, l’équipe data a clairement un rôle à jouer dans la « vie » de la plateforme. Les CDP, par définition et par volonté délibérée, ne favorisent pas la coopération Marketing – IT. Or, c’est la meilleure collaboration des équipes IT et Marketing qu’il faut viser pour gagner en efficacité et en rapidité, pas la mise hors jeu de l’équipe IT qui a un rôle important à jouer dans la valorisation des données clients.
Ceci dit, la distinction entre CDP et Reverse ETL est parfois flottante et ne doit pas être absolutisée. Dans la vraie vie, les choses sont souvent plus complexes et les distinctions nominales à relativiser. On peut définir le Reverse ETL (ou plutôt le Reverse ETL couplé à un Data Warehouse Cloud) comme une CDP souple et sur-mesure. Dans les deux cas, la fonction est bien la même : transformer la donnée répondant aux cas d’usage métier et la redistribuer aux applicatifs sous forme de scores, d’agrégats, d’audiences, de segments…Octolis, d’ailleurs, se définit autant comme un Reverse ETL que comme une Customer Data Platform comme en témoigne sa page d’accueil : 
Différence entre un iPaaS (type Integromat) et un Reverse ETL
Les iPaaS sont des solutions d’intégration en tant que service : Integration Platform as a Service. Integromat, Zapier, Tray.io, Workato, MuleSoft, Jitterbit ou encore Snaplogic sont des exemples parmi d’autres d’iPaaS.
Ce sont des plateformes en général à la fois très puissantes et faciles d’utilisation, comme le montre l’interface intuitive d’Integromat. Les iPaaS permettent de créer facilement des flux de données entre les différentes outils de la stack marketing. Ces outils peuvent être utilisés directement par les profils non-techniques dans la mesure où ils ne nécessitent pas d’utiliser de requêtes SQL. Tous les branchements, toutes les programmations s’effectuent depuis une interface visuelle non-technical user-friendly.
Vous me direz : quel est le talon d’Achille de cette famille de solutions ? Il y en a bien un, qui est le suivant : les iPaaS sont conçus pour créer des passerelles de données « point-à-point » entre les solutions. Par exemple, de synchroniser Salesforce et Hubspot, puis de synchroniser Salesforce à Zendesk, puis de synchroniser, etc. Bref, le problème est là. Vous finissez par vous retrouver avec des centaines de connexions réciproques entre vos dizaines d’outils, ce qui complexifie la maintenance de ce système d’intégration qui ne fait justement pas système.
Cela n’est pas pour faciliter la maintenance des intégrations. Par ailleurs, une solution iPaaS n’offre pas la possibilité de construire des modèles de données personnalisés – modèles personnalisés qui sont nécessaires pour synchroniser correctement les données dans les applicatifs métiers. Un iPaaS ne joue pas le rôle de référentiel client, de base unifiée. Il peut répondre très bien à des besoins d’intégration ponctuels, mais ne remplace pas une solution de type Reverse ETL qui permet, accolé au Data Warehouse, de systématiser l’unification des données et de faciliter leur partage aux métiers.
Si vous vous intéressez aux sujets data, ces articles pourraient aussi vous intéresser :
L’intégration des données dans un Reverse ETL : Event streaming Vs Tabular data streaming
Il y a essentiellement deux manières pour déplacer les données d’un système à l’autre, pour intégrer les données d’un système A dans un système B :
- L’event streaming, qui consiste grosso modo à synchroniser en temps réel les données du système A dans le système B au fur et à mesure de la réalisation des événements : ajout d’une donnée, mise à jour d’une donnée, suppression d’une donnée…
- Le tabular data stream, qui consiste à copier-coller une table ou plusieurs tables du système A dans le système B, en batch : toutes les 2 minutes, toutes les 10 minutes, toutes les heures…Dans ce cas, on déplace non pas une seule donnée (= un événement, par exemple : X a acheté le produit Y le 10/10/2021, Y a visité la page X du site web le 14/08/2021), mais un ensemble de données organisé dans des tableaux – ensembles constituant un agrégat, une liste de scores…
Si l’on souhaite une intégration des données en temps, l’approche event streaming est la seule envisageable. Certains ETL sont basés sur l’approche « event streaming », c’est le cas par exemple de Segment. D’autres utilisent l’approche tabular data, comme Fivetran. Les Reverse ETL quant à eux utilisent les deux modèles d’intégration des données :
- Certains Reverse ETL ont la capacité de se synchroniser en temps réel avec les données du Data Warehouse (approche event streaming).
- Les agrégats de données construits dans la solution Reverse ETL sont ensuite redistribués aux applicatifs métier en batch, qui peuvent être très courts : 5 min, 10 min…Certaines solutions Reverse ETL, comme Octolis, envisagent dans un proche avenir de proposer la capacité à redistribuer en temps réel les données transformées dans les applicatifs cibles. C’est particulièrement prometteur et intéressant, dans la mesure où le temps réel ou le quasi temps-réel est un prérequis pour activer les données comportementales web.

L’évolution de la Stack Data menant à l’avènement du Reverse ETL
Pour expliquer le rôle des Reverse ETL et la différence entre cette nouvelle famille de MarTech et les solutions de type ETL, CDP ou iPaaS, on peut adopter une perspective historique. Dans les années 2000, grosso modo, le CRM était le pivot de l’architecture SI des organisations. C’était la solution qui faisait office de passerelle entre les sources de données et les autres outils d’activation : Marketing Automation, Ticketing…La combinaison CRM + iPaaS jouait le rôle aujourd’hui dévolu aux Reverse ETL. Le CRM était Référentiel Client Unique.
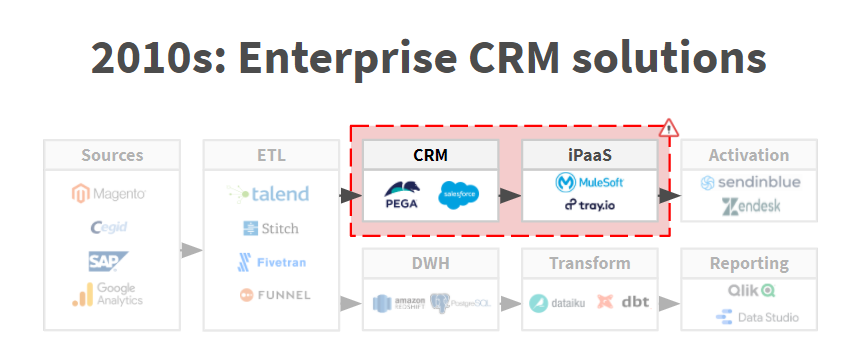
A partir de 2015 – 2016 sont apparues les fameuses Customer Data Platforms. Ces dernières ont suscité l’émergence d’une nouvelle stack data. Cette stack data est toujours d’actualité. Elle consiste à utiliser la CDP pour unifier les données en provenance des différences sources, les transformer en vue des cas d’usage marketing avant de les redistribuer aux outils d’activation. La CDP (comme le CRM dans le schéma précédent) ne remplace pas le Data Warehouse qui sert à stocker et transformer les données en vue des cas d’usage de Business Intelligence.
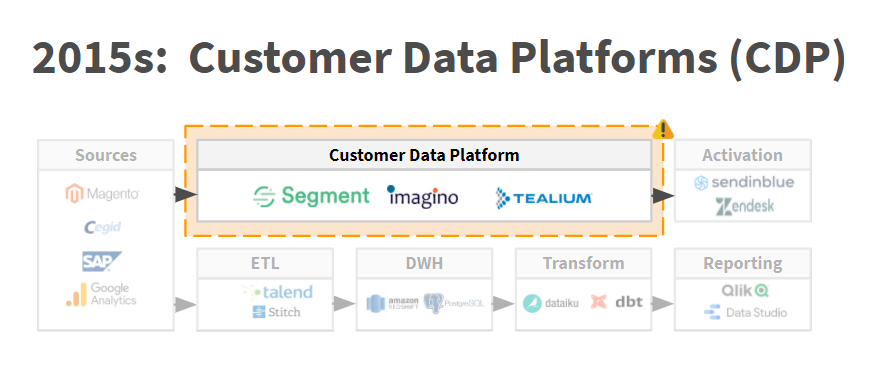
Si l’approche consistant à faire du CRM l’outil pivot de la stack marketing a décliné depuis plusieurs années, il n’en est rien de la deuxième approche basée sur la CDP – approche qui continue de représenter le nec plus ultra pour la plupart des entreprises (y compris les plus matures en matière de data management). Pourtant, et c’est tout l’objet de cet article, l’approche data moderne est bien celle qui place le Data Warehouse au centre de l’architecture IT et qui repose sur l’utilisation d’un Reverse ETL.
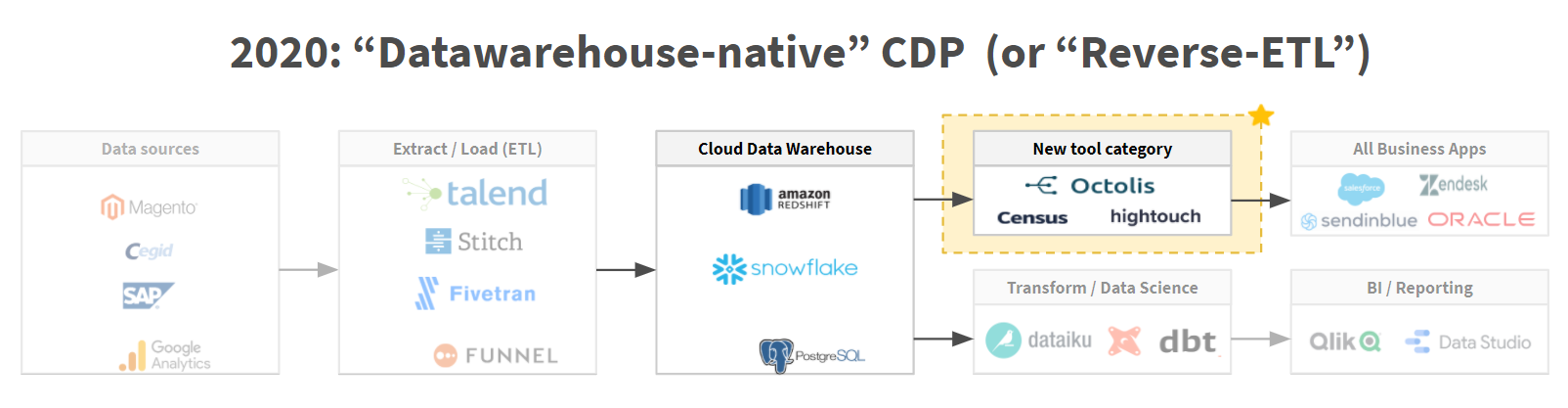
Présentation des principales solutions Reverse ETL du marché
Le marché des Reverse ETL est très jeune. Il existe relativement peu d’acteurs crédibles. Nous allons vous en présenter trois, dont un français (en passe de devenir européen) : Octolis.
Octolis
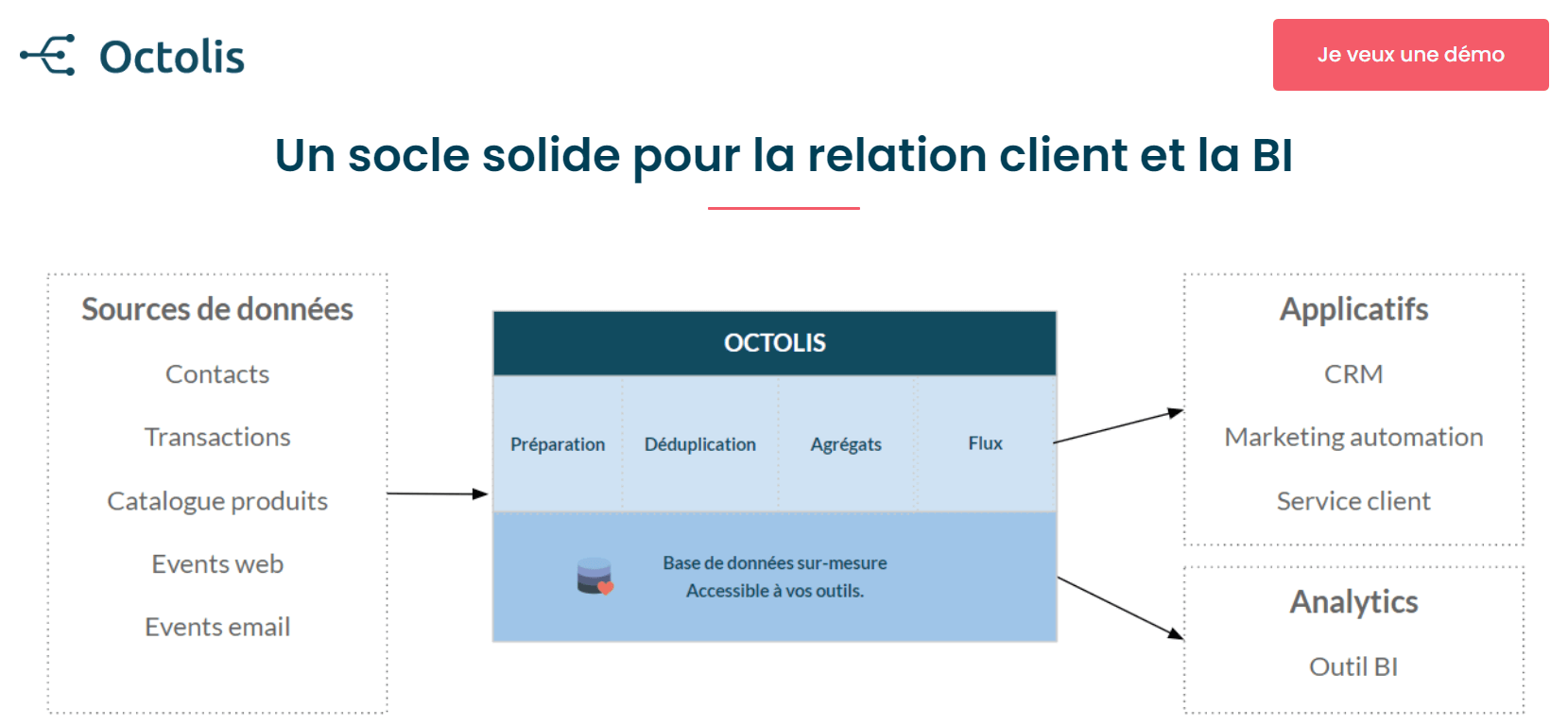
Octolis a été lancé fin 2020 par une équipe dans laquelle figure deux membres de Cartelis : Yassine Hamou Tahra et Clément Galopin. Comptant d’ores et déjà de belles références (KFC notamment), Octolis a conclu en février 2021 deux partenariats avec Sendinblue et Splio pour booster sa croissance. Octolis se positionne comme LA solution Reverse ETL de référence sur le marché français et ambitionne de devenir leader européen sur le marché des CDP sur-mesure pour les entreprises mid-market (PME – ETI).
Octolis remplit toutes les fonctions d’un Reverse ETL, qui se résument à utiliser les données du Data Warehouse pour les cas d’usage opérationnels. Octolis permet de préparer les données issues du Data Warehouse Cloud, de créer à partir de là une vision client 360, de constituer des agrégats de données (via des requêtes SQL ou en mode visuel) et de synchroniser enfin les données dans les applicatifs métiers sous forme de batches.
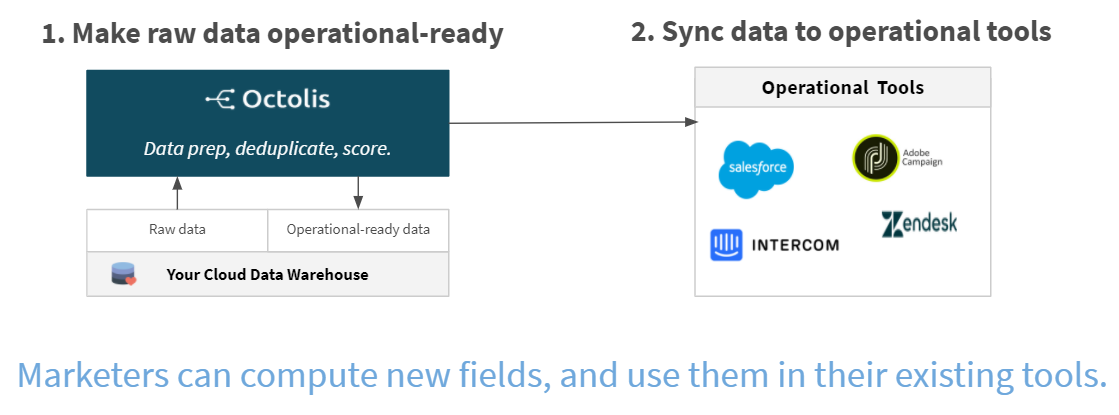
Census
Census est l’un des pionniers sur le marché des Reverse ETL. La solution proposée par cet acteur US permet, à partir des données du DWH, de créer une vision client unique et de construire des agrégats, des segments dynamiques et des scores via du SQL ou une interface visuelle que vous pouvez ensuite synchroniser automatiquement dans les outils comme Salesforce ou Marketo. Census propose d’ailleurs une belle panoplie de connecteurs.

Hightouch
Hightouch a levé plus de 2 millions de dollars fin 2020. Pour l’anecdote, les deux fondateurs d’Hightouch (Tejas Manohar et Josh Curl) travaillaient auparavant chez Segment (CDP). Ils ont été témoin de l’essor des technologies Data Warehouse Cloud comme Snowflake, Google BigQuery ou Amazon Redshift. Ces solutions DWH permettaient enfin aux entreprises de disposer d’une base de données clients unifiée. Tejas et Josh ont alors fait le constat que nous avons rappelé au début de cet article : la sous-utilisation des données du Data Warehouse ou, ce qui revient au même, leur exploitation aux seules fins d’analytics et de BI. C’est de ce constat qu’est née l’idée de construire une solution permettant de mettre à disposition les données du DWH aux équipes opérationnelles, dans leurs outils. Ainsi est née Hightouch qui est l’un des acteurs de référence sur le marché US. L’équivalent US d’Octolis en quelque sorte :).
Vous l’aurez compris, le Reverse ETL est une nouvelle famille d’outils à prendre très au sérieux. Elle répond finalement à deux enjeux :
- Unifier les données clients en vue de leur exploitation par les équipes métier (Marketing, Ventes, Digital, Service Client…). A la différence du Data Warehouse qui unifie les données en vue de cas d’usage en BI. Le Reverse ETL se base sur les données du Data Warehouse auquel il est connecté pour construire de nouveaux modèles d’unification des données et créer, à partir du DWH, un Référentiel Client Unique (et la vision 360 client qui l’accompagne) rendant possible des cas d’usage marketing avancés.
- Faciliter l’intégration des données transformées et organisées par le Reverse ETL (sous forme d’agrégats, de segments, d’audiences, de scores…) dans les applicatifs métiers.
On n’a clairement pas fini d’entendre parler des solutions Reverse ETL tant elles répondent à des besoins de plus en plus impérieux de la part des entreprises. Nous aurons très probablement l’occasion de produire d’autres contenus sur cette technologie d’avenir, nouvelle pièce maîtresse de la stack data moderne.
Laisser un commentaire