Au cœur de la plupart des projets de gouvernance des données se trouve le concept de MDM – Master Data Management – qui vise à créer une source unique de vérité (SSOT) pour différentes entités. Cette démarche est essentielle aussi bien dans les projets CRM marketing que commerciaux. Dans la plupart des organisations, elle a un impact particulièrement fort sur les entités telles que les produits et les clients. L’obtention de résultats et de données propres passe par la déduplication de vos données CRM. En effet, il sera nécessaire d’associer et de fusionner des données de différentes sources pour former cette vue unifiée des entités.
Nous nous sommes inspiré de ce très bon article de Julien Kervizic, publié sur Medium.com et de notre expérience sur le sujet pour vous aider à comprendre comment unifier vos données clients.
Stratégie de matching
Méthode d’appariement
Il existe différents types de concordance qui peuvent être réalisés à partir de règles automatisées pour faire correspondre les données entre elles, ou les faire passer par un processus d’examen.
Les méthodes de comparaison utilisées peuvent être configurées de manière à traiter différentes certitudes de comparaison. Les correspondances les plus certaines sont soumises à un processus automatisé et les plus incertaines à un processus de révision. Ce type d’approche peut être utile pour obtenir les échantillons appropriés afin de former un modèle de prédiction.
Types de concordance
Il existe différents types d’appariement possibles, de l’appariement exact, à l’appariement phonétique, à la propension, à l’appariement flou ou négatif.
Correspondance exacte : Une correspondance exacte repose sur la capacité à relier deux sources d’information différentes en fonction de l’existence d’une clé spécifique permettant de faire correspondre les informations. Il peut s’agir, par exemple, d’un code EAN pour les produits ou d’un numéro d’identité national.
Correspondance phonétique : Il peut arriver qu’une correspondance exacte ne suffise pas pour gérer la fusion d’informations. C’est généralement le cas lorsque les données doivent être saisies à la main sur la base d’une saisie vocale. Par exemple, l’enregistrement d’un nom ou d’une adresse dans un système de point de vente (POS). Lorsque cela se produit, nous devons être en mesure d’assouplir l’algorithme de correspondance pour traiter des cas phonétiquement similaires.
En python, la bibliothèque de phonétique intègre quelques-uns des algorithmes de correspondance phonétique les plus populaires. En général, ces algorithmes fonctionnent bien pour l’anglais, mais ne prennent pas en charge les autres langues.

Dans l’exemple ci-dessus, nous pouvons voir comment Julien et Julian, ont la même représentation phonétique en utilisant l’algorithme Soundex.
Correspondance floue : Une « fuzzy match » est une correspondance qui n’est pas exacte. Une partie de son application consiste à permettre différents types d’orthographe ou de faute d’orthographe en entrée, en faisant correspondre les utilisateurs lorsque d’autres critères correspondent et que leur adresse se trouve dans un certain rayon les uns des autres. Le tutoriel suivant de datacamp montre comment comparer les différentes chaînes de caractères et générer un score permettant cette correspondance inexacte.
Correspondance de propension : La correspondance par propension fournit un type différent de correspondance exacte, mais cette fois-ci en s’appuyant sur un modèle de prédiction pour produire la valeur probable de la validité d’une correspondance.
Correspondance négative : L’appariement négatif fournit des conditions et des règles d’exclusion supplémentaires sur les cas où il ne faut pas apparier deux données ensemble. Elles peuvent être utilisées pour exclure un événement peu probable.

Un exemple de cas où des correspondances négatives pourraient être utilisées est présenté ci-dessus. Lorsque l’on compare deux séries de données liées à des utilisateurs et que l’on constate la distance entre les enregistrements.
Ce type de concordance négative, lorsqu’il est mis en œuvre dans un workflow, pourrait faire en sorte qu’une concordance automatisée ne soit pas appliquée, mais qu’elle soit tout de même signalée pour un examen manuel.
Considérations
Il y a de multiples considérations à prendre en compte lorsque l’on envisage de fusionner des données. Les entités peuvent avoir plusieurs noms, les langues peuvent avoir un impact dans le cas de noms, de lieux ou d’adresses, les données doivent être normalisées et un nettoyage des données est généralement nécessaire avant de faire correspondre les différents attributs.
Fréquence des noms : Lors de la mise en déduplication des données CRM, l’un des facteurs à prendre en considération est la fréquence des noms. Des noms différents et des fréquences d’occurrence différentes, ainsi que des noms communs, nécessitent une charge de preuve plus élevée avant d’être mis en correspondance.
Pseudonymes et autres noms : Il convient de noter que différentes entités peuvent avoir des nomenclatures alternatives, qu’elles soient officielles, des noms de scène ou des pseudonymes.
Les langues : Les langues ont tendance à être une considération essentielle à avoir dans l’appariement des différentes entités. Prenez, par exemple, la mise en correspondance de diverses sources en anglais et en chinois. L’entité peut être la même, mais il existe différentes représentations du même nom selon les langues.
La déduplication de données CRM qui mixent plusieurs langues dépend fortement d’un modèle de données multilingues approprié, associé à des données de liaison entre les langues.
Abréviations : Les abréviations ont une incidence sur la manière dont les différents enregistrements de texte peuvent devoir être mis en correspondance. Du raccourcissement des prénoms, comme Bill pour William ou Pete pour Peter, aux abréviations de titre comme Dr. pour Doctor, elles rendent plus difficile la recherche de correspondances sans traitement supplémentaire.
Nettoyage des données et normalisation des données : Essayer de faire correspondre des champs de texte différents nécessite également un certain degré de nettoyage des données. Qu’il s’agisse de la gestion des espaces, des caractères spéciaux et des ponctuations ou de la correction des fautes d’orthographe, il existe de nombreuses mesures à prendre pour normaliser les données et permettre de trouver une correspondance exacte.
Contactez Cartelis
pour enfin capitaliser sur vos données clients.
Cartelis vous accompagne dans le cadrage et le déploiement d'une stratégie data et CRM vraiment impactante.
Analyse client, Choix des outils, Pilotage projet et Accompagnement opérationnel.
Prendre contact avec CartelisStratégie d’autorité
Une stratégie d’autorité aide à définir les domaines de la stratégie qui doivent être considérés comme la source d’information faisant autorité lorsque des informations contradictoires sont fournies.
Hiérarchie
La hiérarchie des autorités permet de définir une préférence pour le prélèvement de certains types d’informations auprès de différentes sources. La logique qui sous-tend ce type de stratégie est que certaines sources d’information doivent être considérées comme des « sources de confiance », tandis que d’autres disposent d’informations de qualités différentes.
Examinons les informations contenues dans une base de données gouvernementale sur l’identité et les noms nationaux. Nous pouvons considérer qu’il s’agit d’une source d’information hautement fiable. Comparons cela à un formulaire de saisie sur un site web, sur un site où des fautes de frappe ou de mauvaises saisies peuvent se produire tant pour l’identité que pour les noms.
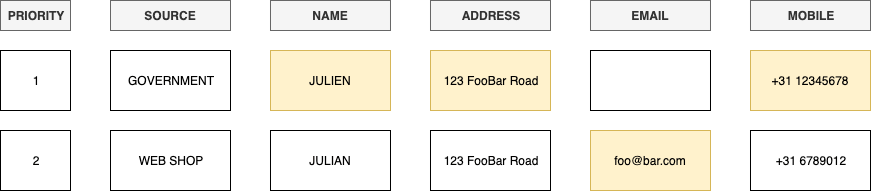
L’exemple ci-dessus montre comment une stratégie de hiérarchie globale pourrait fonctionner en sélectionnant (en jaune) des attributs de profil dans un enregistrement consolidé.
Limitation dans le temps
Les différents domaines d’information peuvent être « muables », c’est-à-dire qu’ils sont susceptibles de changer. Il est important de savoir comment traiter l’information dans le temps.
Les champs tels que les noms sont relativement immuables. Ils peuvent techniquement changer – par exemple, lors d’un mariage ou d’une demande de changement de nom auprès du gouvernement. Mais dans la majorité des cas, ils ne changent pas fréquemment.
D’autres champs, tels qu’une adresse ou un numéro de téléphone, ont plus tendance à être modifiables. Les domaines qui ont une plus grande tendance à muter ont tendance à bénéficier davantage de l’application d’une stratégie d’autorité basée sur le temps. Vous souhaitez disposer de la source d’information la plus récente.
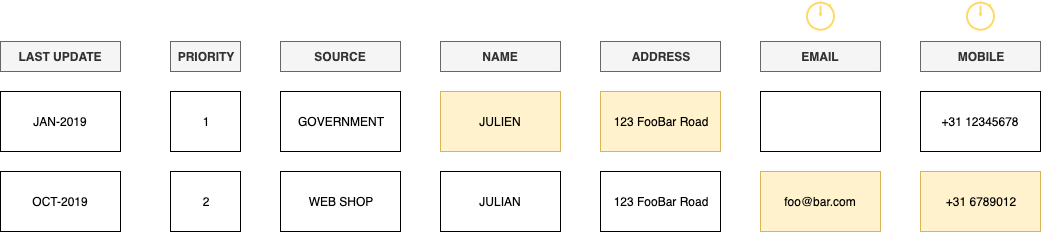
Le tableau ci-dessus montre ce qui arriverait à l’attribut sélectionné dans le profil consolidé si nous étendions l’exemple précédent avec une stratégie d’autorité limitée dans le temps pour l’adresse email et le numéro de téléphone.
Règle de vote
Lorsque l’on a affaire à plusieurs sources d’information pour les mêmes domaines, il peut être avantageux d’appliquer une stratégie d’autorité de règle de vote. Le domaine faisant autorité serait défini par un vote majoritaire entre les différentes sources d’information.
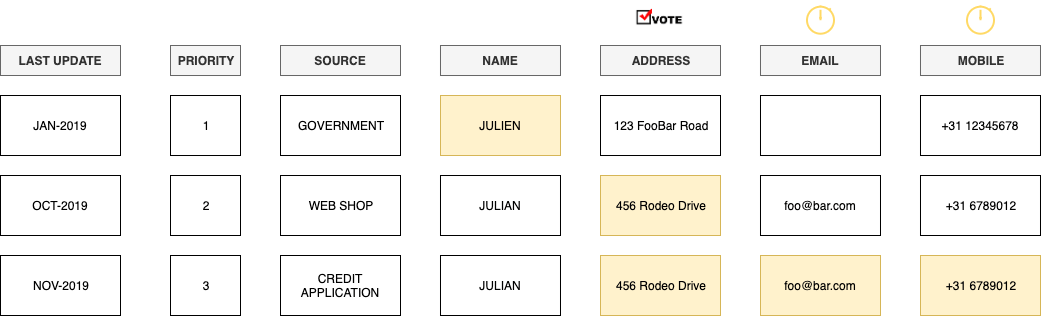
En étendant l’exemple ci-dessus avec une stratégie de vote pour le champ d’adresse, nous pouvons constater que l’adresse fournie par la source de données gouvernementale n’est plus sélectionnée pour le profil unifié.
Considérations
Les types de stratégie de l’autorité qui doit être appliquée devraient être très dépendants du terrain.
Stratégie à plusieurs niveaux : En fonction du nombre de sources de données disponibles, il peut être utile de regrouper les sources de données par classes et d’appliquer une stratégie d’autorité à plusieurs niveaux sur ces différents domaines.
Dépend du temps : Quelle que soit la stratégie utilisée, le temps sera toujours un facteur dans une certaine mesure. Il est important de placer une limite temporelle sur la plupart des champs pour appliquer la stratégie.
Stratégie de consolidation
Cette stratégie dicte la manière dont les documents sont fusionnés. Il existe généralement deux types différents de stratégies de consolidation : la fusion dure et la fusion douce. La fusion dure consolide plusieurs enregistrements en un seul, tandis que la stratégie de fusion douce crée une association entre les différents enregistrements qui, lorsqu’ils sont lus, doivent être regroupés.
« Hard merge »
Dans le cadre d’une fusion « hard », les données peuvent être fusionnés en utilisant une stratégie de fusion avant ou une stratégie de fusion arrière.
Une fusion « hard » présente des avantages tels que la réduction de la taille de la base de données, des requêtes plus efficaces et la facilité d’extraction de ces champs d’autorité.
Il existe cependant quelques inconvénients, dont les trois principaux sont :
- La perte de données
- La fusion irréversible
- Toutes les stratégies d’autorité ne sont pas compatibles avec la fusion « hard »
La stratégie de fusion en avant, liera les les données ensemble après qu’une condition de correspondance ait été remplie. Elle n’aura pas d’impact sur les enregistrements historiques.
La stratégie de fusion vers l’arrière, liera les enregistrements en arrière historiquement et fusionnera ensemble les différents enregistrements qui ont été identifiés avec des conditions de correspondance.
Dans ce cas, les données relatives aux deux profils sont fusionnées en un seul, à la fois historiquement et au fil du temps. Dans le code, ce type de stratégie peut être mis en œuvre sous la forme d’une fusion initiale des événements liés aux deux profils et d’une redirection de l’identifiant.
Si vous vous intéressez aux sujets data, ces articles pourraient aussi vous intéresser :
Fusion douce (Association)
Les stratégies de fusion douce reposent sur une association à créer entre les différents documents. Comme pour la fusion dure, deux principaux sous-types de stratégies peuvent être appliqués, une association complète ou une association avec des conditions de filtrage.
L’un des principaux avantages de la stratégie de fusion douce est que l’association peut toujours être annulée. Elle présente cependant quelques inconvénients en termes d’espace et de performances.
Association complète
Une association complète fournit un dossier d’association pour les différentes entités fournies. L’association complète permet à la fois d’extraire les activités en cours à travers les différentes identités, mais aussi de tirer parti des données historiques grâce à elle.
Nous devons incorporer un moyen de :
- Stocker les associations
- Ajouter des associations
- Interroger les informations pertinentes obtenues par l’association
En suivant le même schéma que dans l’exemple précédent et en effectuant l’association. Nous pouvons voir comment l’ensemble des événements est maintenant capturé après l’association.
Mais contrairement à l’approche de fusion des profils, il est toujours possible de récupérer les événements directement associés à chaque profil.
Association avec filtrage
Une association avec le filtrage permet de mieux contrôler la manière dont les différents points de données seront consolidés. Elle nous permet de mettre en œuvre une sorte de fusion en amont seulement en tant qu’association, utile lorsque vous ne pouvez exploiter l’enregistrement commun que si un utilisateur a accepté de nouvelles conditions de service, par exemple.
Contrairement à la stratégie de fusion avancée, il est possible d’adopter le point de vue du profil 1 et du profil 2.
Considérations
Volume des données : Le volume global de données est un facteur qui joue dans la décision de la stratégie à appliquer. Prenez en compte les identifiants transitoires tels que les identifiants de session de site web, chacun pouvant créer un profil temporaire. Un utilisateur donné peut avoir des centaines de profils temporaires et potentiellement un profil connecté. Pour obtenir le profil faisant autorité, l’application devrait passer par tous ces profils temporaires et appliquer la stratégie d’autorité.
Unicité des correspondances : La stratégie de correspondance peut devoir traiter des correspondances non uniques. Dans le cas d’une stratégie de fusion douce, seule une clé d’association devrait être ajoutée pour traiter correctement cette information. Dans le cas d’une fusion dure, cela peut conduire à la duplication des informations dans les enregistrements clés.
Performance et complexité : L’utilisation d’une stratégie de fusion douce offre généralement des performances de lecture plus faibles qu’une stratégie de fusion dure.
Correspondances incertaines : Différents types de stratégies de mise en correspondance et d’identifiants conduisent à un risque différent de mise en correspondance d’enregistrements qui n’appartiennent pas à un même ensemble.
Réglementation : La réglementation joue parfois un rôle dans la manière dont les enregistrements doivent être fusionnés. Il peut, par exemple, dicter quelles données doivent être disponibles pour être utilisées dans un profil consolidé ou quelles données peuvent être utilisées à quelle fin. L’association avec le filtrage est la stratégie de consolidation qui répondrait le plus facilement à différents règlements, mais aussi la plus complexe à intégrer.
Si vous souhaitez mieux gérer vos données CRM, je vous invite fortement à parcourir ces articles :
- Gérer la migration des données CRM : méthodologie et meilleures pratiques
- Découvrez comment mener une analyse de votre base de données clients/CRM
- Référentiel données client : le guide complet pour intégrer et unifier vos données clients
Laisser un commentaire